并发整体设计
Go调度器的主要函数为 schedule,但是由于版本迭代新功能的不断增加,该函数的流程也越来越复杂,本系列计划从一个最简单的调度器开始,一步一步添加功能,来实现完整的Go调度器,也便于大家理解每部分的作用。
简单来说,Go从语言层面支持了协程,使用go 关键字创建协程;Go的协程(goroutine)是轻量级的线程,是“有栈”的,每个Goroutine默认的栈大小为2KB;支持自动扩缩容;由Go的调度器提供了一种M:N的调度模型,在用户态而非内核态进行调度。
TODO: 1:1、1:N、M:N 调度模型
除了创建协程,还提供了协程级别的sleep、mutex、signal等。
为了保障并发安全,提供了原子操作、mutex、channel、waitGroup等等并发原语。
注:协程中的“协”,本意为协作式,但是从实现上来说,Goroutine的调度方式并不完全是协作式的。如果每个Goroutine只有主动调用runtime.Gosched()才会释放执行权的话,是协作式的,但是Go还会在安全点抢占运行时间过长的Goroutine,以及go1.14中加入的基于信号的抢占式调度,都使得Goroutine可能会在程序员不感知的情况下被切换。
调度器与操作系统的交互
TODO: 补充
或者说需要操作系统提供的能力
-
多线程
clone 系统调用
pthread库
-
原子操作
x86对应的汇编指令
-
线程锁
futex信号量 + 原子操作
朴素调度器
注:环境信息 x86 Linux/Macos
源码地址:https://github.com/WangLeonard/go/commits/dev-schedule
作者认为,调度器其实只需要保证所有的可运行的Goroutine终将被执行,就足够了。当然也应该考虑调度时延,内存占用,调度效率,低负载时的Cpu使用率等等,但这些并不影响程序或者说协程定义的正确性。
那么如何实现最低标准的M:N调度模型的协程调度器呢?
先来看一个简单的例子,该例子中使用go关键字创建了一个Goroutine。
对于go func的行为预期应该是什么?是否需要等待对应的协程开始运行或是执行完成才返回,或者说是否main函数在调用go func之后是否会阻塞等待其被执行或是执行完成,答案是否定的。从执行结果来看,该程序只有小概率会打印出"Hello Goroutine",大部分情况下打印"Hello Main"之后便退出了。
package main
import (
"fmt"
)
func main() {
go func() {
fmt.Println("Hello Goroutine")
}()
fmt.Println("Hello Main")
}
所以这里需要将提交任务和执行任务进行“解耦”,可以将其想象为“生产者-消费者”模型,需要一个“容器”来存储待运行的Goroutine,可以选择一个无界、线程安全的队列来存储提交给调度器的Goroutine。
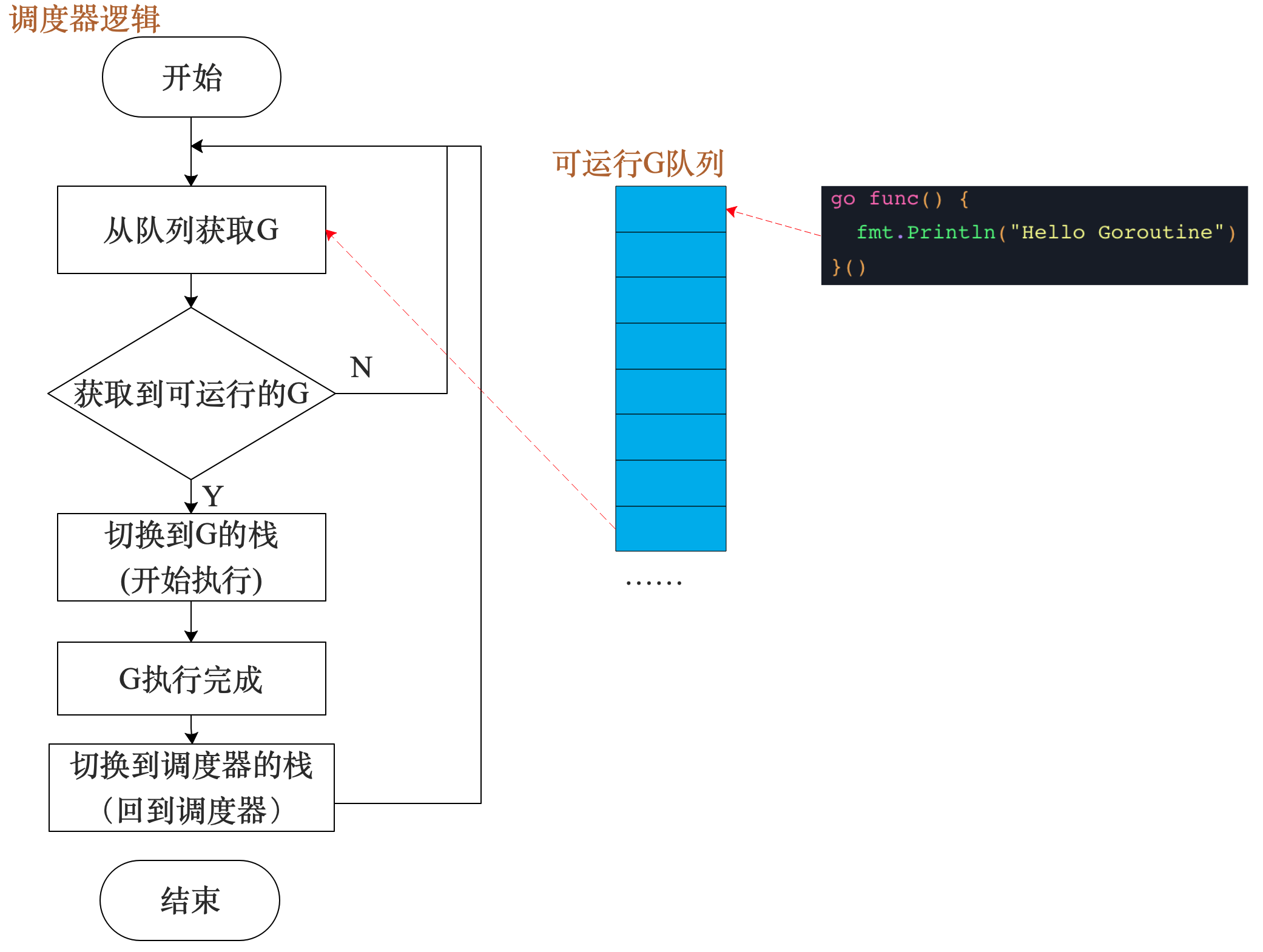
朴素调度器逻辑伪代码如下
func schedule() {
for {
gp := globrunqget()
if gp != nil {
run(gp)
}
}
}
创建协程
继续分析go func的行为
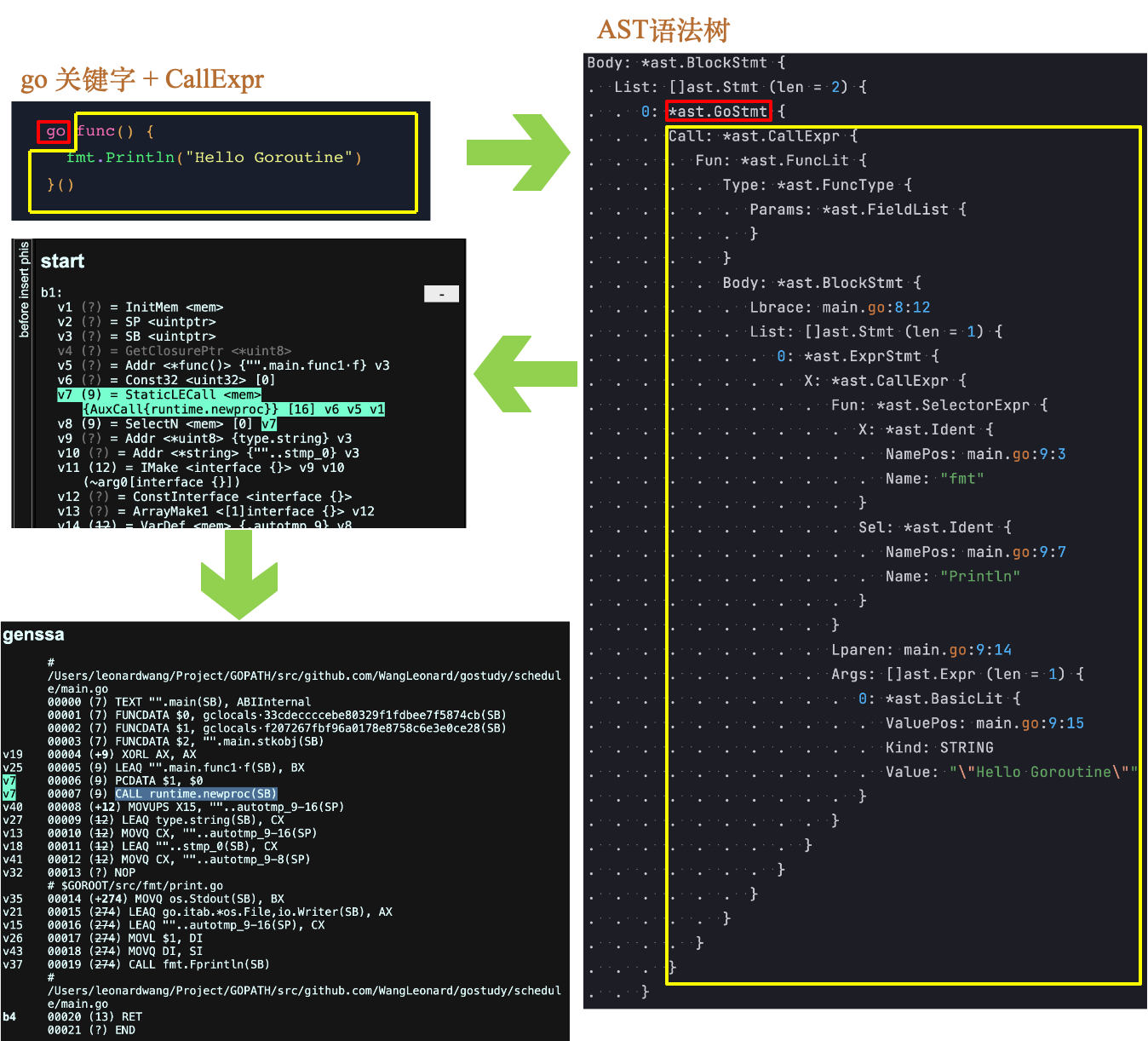
go关键字和其后跟随的func会被转换为对runtime.newproc函数的调用。
在何时启动多线程
继续分析runtime.newproc函数需要做的事情,分为以下几个部分
-
初始化Goroutine
-
提交Goroutine到任务队列
-
“按需”创建操作系统线程
调度器需要在一个合适的时间点来创建新的线程,来达到多线程并行调度的目的,在向调度器提交任务时可以作为一个合适的时间点,在朴素调度器中由于操作系统线程被创建后会一直从任务队列查询是否有需要运行的Goroutine,不会进入空闲等待的状态,所以有需要时,直接创建新的操作系统线程,线程的入口函数会做一些初始化之后进入调度逻辑寻找Goroutine来执行。
那么创建线程的数量也应该有一个限制,否则每次提交Goroutine都创建一个新的操作系统线程,就无法达到轻量的目的了,在朴素调度器中可以简单的将线程最大数量限制为cpu核心数(最终版本中是根据P的数量进行限制)。所以下图中的“需要创建线程”条件具体为“当前线程数量是否到达了CPU核心数”。
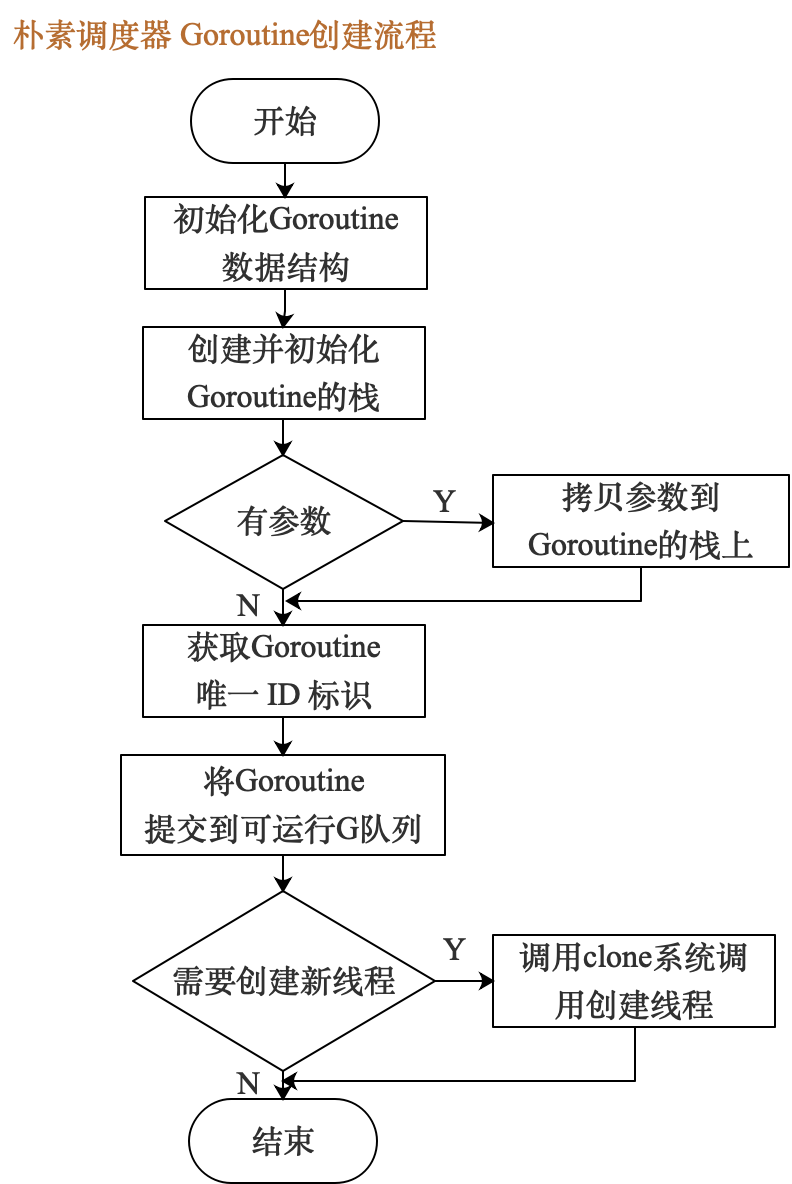
任务队列
这里就是一个需要线程锁来保证线程安全的、使用链表实现的无界队列,提供了put和get方法
协程运行完成如何回到调度器
调度器找到一个可运行的Goroutine后,切换到它的栈进行运行,那么协程执行结束后如何再回到调度器,使得调度器可以继续执行任务呢?
简单来说,实际提交到调度器的任务,是被“包裹”了一层,在新函数中调用要执行的任务,并在后方插入回到调度器的函数。
比如说go Hello()
func Hello() {
fmt.Println("Hello World")
}
func main() {
go Hello()
}
实际执行的任务其实是:(伪代码)
func goexit(){
Hello()
switchToSchedule() // mcall(schedule)
}
所以在Hello执行完成后会回到goexit函数,并执行后续的switchToSchedule,进而重新回到调度器。
注:mcall的实现在栈切换中进行详解
栈切换
Cpu如何认为这是一个栈?
SP、BP寄存器的作用
SP:堆栈寄存器SP(stack pointer)存放栈的偏移地址;
BP: 基数指针寄存器BP(base pointer)是一个寄存器,它的用途有点特殊,是和堆栈指针SP联合使用的,作为SP校准使用的,只有在寻找堆栈里的数据和使用个别的寻址方式时候才能用到
SP用以指示栈顶的偏移地址,**而BP可 作为堆栈区中的一个基地址,用以确定在堆栈中的操作数地址。
按照这个规则,从CPU的角度来说,SP寄存器指向的位置就是栈空间,我们可以通过汇编指令的方式来直接操作SP物理寄存器,我们可以通过这种方式来“欺骗”CPU将Goroutine的栈空间认为是栈。
如前方所述,Go的协程是“有栈”的,即每个Goroutine有自己独立的栈空间。
再来看一个老生常谈的问题,堆和栈的区别
https://www.zhihu.com/question/19729973
C++ 中堆和栈的区别
管理方式:栈由编译器自动管理,无需人为控制。而堆释放工作由程序员控制,容易产生内存泄漏(memory leak)。
空间大小:在32位系统下,堆内存可以达到4G的空间,但对于栈来说,一般都是有一定的空间大小的(在VC6默认的栈空间大小是1M,也有默认2M的)。
生长方向:堆生长(扩展)方向是向上的,也就是向着内存地址增加的方向;栈生长(扩展)方向是向下的,是向着内存地址减小的方向增长。
分配方式:堆都是动态分配的,没有静态分配的堆。而栈有2种分配方式:静态分配和动态分配。静态分配是编译器完成的,如局部变量分配。动态分配由alloca函数进行分配,但是栈的动态分配和堆是不同的,它的动态分配是由编译器进行释放,无需我们手工实现。
效率:栈是机器系统提供的数据结构,计算机会在底层对栈提供支持(有专门的寄存器存放栈的地址,压栈出栈都有专门的机器指令执行),这就决定了栈的效率比较高。堆则是C/C++函数库提供的,它的机制是很复杂的。例如分配一块内存,堆会按照一定的算法,在堆内存中搜索可用的足够大小的空间,如果没有(可能是由于内存碎片太多),就有可能调用系统功能去增加程序数据段的内存空间,这样就有机会分到足够大小的内存,然后进行返回。总之,堆的效率比栈要低得多。
这些规则在Go中不完全适用,首先,堆和栈其实都是内存,调用sysmap从操作系统申请一块内存在Runtime内部手动管理,这些内存既可以作为堆内存也可以使其作为栈。
Go中的栈分为两种,g0的栈(线程栈),用来运行runtime内部逻辑,一般来说比较大,在没有cgo的情况下,栈空间为8KB(使用clone系统调用,并传入栈空间地址),有cgo的情况下,调用pthread直接创建线程,Linux中默认为8MB?
栈切换,其实就是在g0和不同的g栈中互相切换,切换包括保存当前的SP、BP、调用者压栈的reture address 等物理寄存器到g 结构体的sched字段,然后开始恢复要切换到的栈的信息,恢复完成后调用 jmp return address 开始执行。
由于每个G有独立的栈空间,所以在栈切换的过程中无需单独保存局部变量等在栈上的信息。
TODO:如何理解g0?
如何理解栈的分配和释放是由编译器进行管理的?
这里涉及call指令(push return address 并跳转到 具体地址继续执行)和ret指令(pop return address 并跳回return address )的实现;另外栈的申请,其实是对SP寄存器的值进行减法操作(栈的生长方式是向下的),释放栈,是对SP寄存器进行加法操作;编译器也会自动保存和恢复BP的值。
func Test() {
a := 1
b := 2
c := a + b
fmt.Println(c)
}
func main() {
Test()
}
go tool compile -S ./main.go
"".Test STEXT size=103 args=0x0 locals=0x40 funcid=0x0
0x0000 00000 (./main.go:9) TEXT "".Test(SB), ABIInternal, $64-0
0x0000 00000 (./main.go:9) CMPQ SP, 16(R14)
0x0004 00004 (./main.go:9) PCDATA $0, $-2
0x0004 00004 (./main.go:9) JLS 95
0x0006 00006 (./main.go:9) PCDATA $0, $-1
0x0006 00006 (./main.go:9) SUBQ $64, SP # 申请栈空间
0x000a 00010 (./main.go:9) MOVQ BP, 56(SP) # 在栈上保存当前BP
0x000f 00015 (./main.go:9) LEAQ 56(SP), BP # 更新BP
0x0014 00020 (./main.go:9) FUNCDATA $0, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
0x0014 00020 (./main.go:9) FUNCDATA $1, gclocals·f207267fbf96a0178e8758c6e3e0ce28(SB)
0x0014 00020 (./main.go:9) FUNCDATA $2, "".Test.stkobj(SB)
0x0014 00020 (./main.go:14) MOVL $3, AX
0x0019 00025 (./main.go:14) PCDATA $1, $0
0x0019 00025 (./main.go:14) CALL runtime.convT64(SB)
0x001e 00030 (./main.go:14) MOVUPS X15, ""..autotmp_13+40(SP)
0x0024 00036 (./main.go:14) LEAQ type.int(SB), CX
0x002b 00043 (./main.go:14) MOVQ CX, ""..autotmp_13+40(SP)
0x0030 00048 (./main.go:14) MOVQ AX, ""..autotmp_13+48(SP)
0x0035 00053 (<unknown line number>) NOP
0x0035 00053 ($GOROOT/src/fmt/print.go:274) MOVQ os.Stdout(SB), BX
0x003c 00060 ($GOROOT/src/fmt/print.go:274) LEAQ go.itab.*os.File,io.Writer(SB), AX
0x0043 00067 ($GOROOT/src/fmt/print.go:274) LEAQ ""..autotmp_13+40(SP), CX
0x0048 00072 ($GOROOT/src/fmt/print.go:274) MOVL $1, DI
0x004d 00077 ($GOROOT/src/fmt/print.go:274) MOVQ DI, SI
0x0050 00080 ($GOROOT/src/fmt/print.go:274) CALL fmt.Fprintln(SB)
0x0055 00085 (./main.go:15) MOVQ 56(SP), BP # 恢复BP
0x005a 00090 (./main.go:15) ADDQ $64, SP # 释放栈空间
0x005e 00094 (./main.go:15) RET
"".main STEXT size=40 args=0x0 locals=0x8 funcid=0x0
0x0000 00000 (./main.go:17) TEXT "".main(SB), ABIInternal, $8-0
0x0000 00000 (./main.go:17) CMPQ SP, 16(R14)
0x0004 00004 (./main.go:17) PCDATA $0, $-2
0x0004 00004 (./main.go:17) JLS 33
0x0006 00006 (./main.go:17) PCDATA $0, $-1
0x0006 00006 (./main.go:17) SUBQ $8, SP
0x000a 00010 (./main.go:17) MOVQ BP, (SP)
0x000e 00014 (./main.go:17) LEAQ (SP), BP
0x0012 00018 (./main.go:17) FUNCDATA $0, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
0x0012 00018 (./main.go:17) FUNCDATA $1, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
0x0012 00018 (./main.go:18) PCDATA $1, $0
0x0012 00018 (./main.go:18) CALL "".Test(SB)
0x0017 00023 (./main.go:19) MOVQ (SP), BP
0x001b 00027 (./main.go:19) ADDQ $8, SP
0x001f 00031 (./main.go:19) NOP
0x0020 00032 (./main.go:19) RET
g0 -> g栈的切换
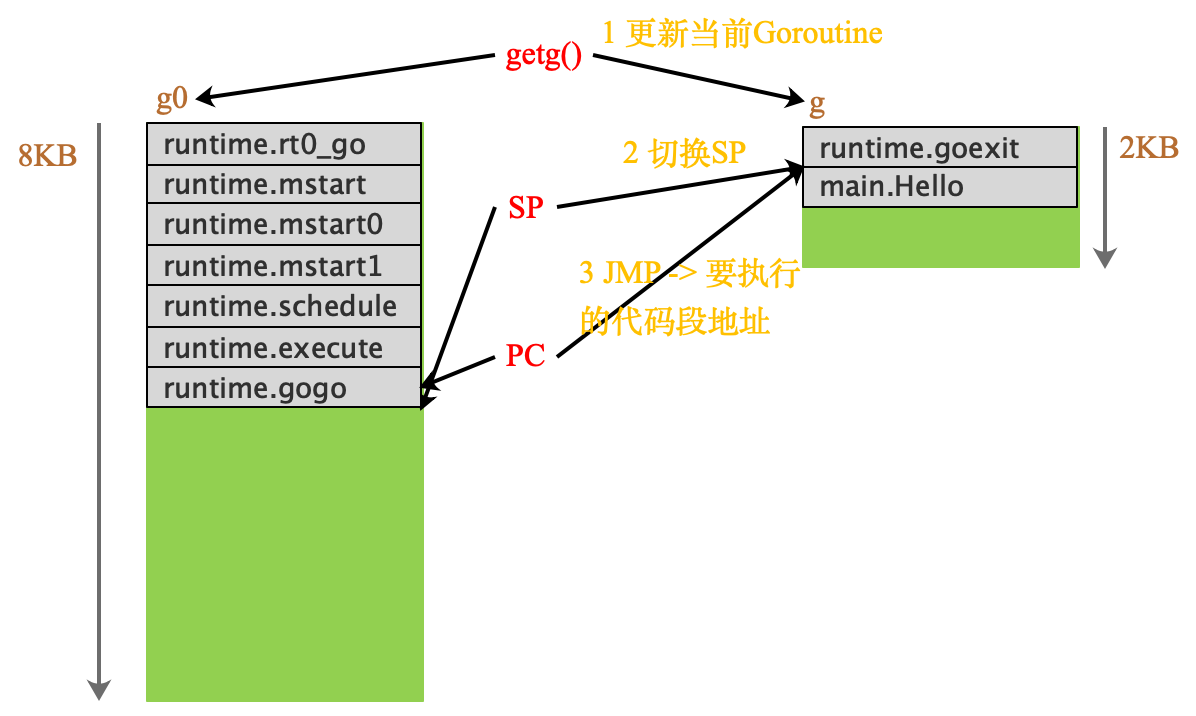
g->g0栈的切换
这里考虑在Goroutine执行结束时的情况
main.Hello 执行结束时,回到runtime.exit函数中,进而调用mcall(schedule)

这里有个细节,为什么切换回g0时的SP指向了mstart,而不是g0->g切换时的runtime.gogo
这里要看g0的sched gobuf中存储的SP和PC信息
创建线程时指定的mstart会调用到mstart1函数,在这个函数中存储,调用mstart1(mstart)时的PC和SP到gobuf中,g->g0时根据这个信息来切栈后,使用CALL执行调用具体要在g0栈中执行的schedule函数。
func mstart1() {
_g_ := getg()
if _g_ != _g_.m.g0 {
throw("bad runtime·mstart")
}
// Set up m.g0.sched as a label returning to just
// after the mstart1 call in mstart0 above, for use by goexit0 and mcall.
// We're never coming back to mstart1 after we call schedule,
// so other calls can reuse the current frame.
// And goexit0 does a gogo that needs to return from mstart1
// and let mstart0 exit the thread.
_g_.sched.g = guintptr(unsafe.Pointer(_g_))
_g_.sched.pc = getcallerpc()
_g_.sched.sp = getcallersp()
// ……
}
实际上在不考虑cgo回调go的场景下时,g0的栈中,在mstart下面不应该再存在任何有价值的栈空间,g0栈只用来临时执行一些栈空间消耗较大的runtime函数。
这里有两个“新名词”getg和gobuf
对于切栈,有几个被封装过的函数
systemstack
mcall
gogo
TODO:为什么不需要保存寄存器?
正确性验证
package main
import (
"sync/atomic"
)
var flag = false
var atomicValue int64
const goroutineCount = 100
func main() {
println("main")
for i := 0; i < goroutineCount; i++ {
go func() {
atomic.AddInt64(&atomicValue, 1)
}()
}
go func() {
println("goroitine begin")
flag = true
println("goroitine done")
}()
for atomic.LoadInt64(&atomicValue) != goroutineCount || flag != true {
// Just like sleep
}
println("Done")
println(atomic.LoadInt64(&atomicValue))
}
go build
GODEBUG=newschedule=1 ./schedule
除去日志打印,该程序终将打印如下信息,并可以正常退出
Done
100
源码实现详解
创建协程
func newproc(siz int32, fn *funcval) {
argp := add(unsafe.Pointer(&fn), sys.PtrSize)
gp := getg()
pc := getcallerpc()
systemstack(func() { // 切换到g0栈执行
newg := newproc1(fn, argp, siz, gp, pc) // 创建g的数据结构以及构造初始栈
if debug.newschedule == 1 {
lock(&sched.lock)
globrunqput(newg) // 加入全局队列
unlock(&sched.lock)
}
if mainStarted {
wakep() // 如果main Goroutine已启动,尝试唤醒新的线程
}
})
}
func newproc1(fn *funcval, argp unsafe.Pointer, narg int32, callergp *g, callerpc uintptr) *g {
_g_ := getg()
acquirem() // 关闭抢占
siz := narg
siz = (siz + 7) &^ 7
if newg == nil {
newg = malg(_StackMin) // 创建一个G的结构体
casgstatus(newg, _Gidle, _Gdead) // G的状态变化 _Gidle -> _Gdead
allgadd(newg) // 添加到全局Goroutine列表
}
totalSize := 4*sys.PtrSize + uintptr(siz) + sys.MinFrameSize // extra space in case of reads slightly beyond frame
totalSize += -totalSize & (sys.StackAlign - 1) // align to StackAlign
sp := newg.stack.hi - totalSize
spArg := sp
if usesLR {
// caller's LR
*(*uintptr)(unsafe.Pointer(sp)) = 0
prepGoExitFrame(sp)
spArg += sys.MinFrameSize
}
if narg > 0 {
// 拷贝参数到Goroutine的栈上
memmove(unsafe.Pointer(spArg), argp, uintptr(narg))
}
memclrNoHeapPointers(unsafe.Pointer(&newg.sched), unsafe.Sizeof(newg.sched))
newg.sched.sp = sp
newg.stktopsp = sp
// 在栈底埋入goexit
newg.sched.pc = abi.FuncPCABI0(goexit) + sys.PCQuantum // +PCQuantum so that previous instruction is in same function
newg.sched.g = guintptr(unsafe.Pointer(newg))
gostartcallfn(&newg.sched, fn)
newg.gopc = callerpc
newg.ancestors = saveAncestors(callergp)
newg.startpc = fn.fn
// G的状态变化 _Gdead -> _Grunnable
casgstatus(newg, _Gdead, _Grunnable)
// 为每个Goroutine分配唯一ID
newg.goid = atomic.Xaddint64(&sched.goidCount, 1) - 1
releasem(_g_.m) // 开启抢占
return newg
}
唤醒线程
准确的说,应该是按需唤醒或创建操作系统线程。
func wakep() {
startm(nil, true)
}
func startm(_p_ *p, spinning bool) {
if debug.newschedule == 1 {
if atomic.Loadint64(&sched.mCount) < int64(ncpu) && atomic.Xaddint64(&sched.mCount, 1) < int64(ncpu) {
newStartm()
}
}
}
//go:nowritebarrierrec
func newStartm() {
mp := acquirem()
lock(&sched.lock)
nmp := mget() // 获取空闲的M
if nmp == nil {
// 如果没有空闲的M 则创建新的 M / 操作系统线程
id := mReserveID()
unlock(&sched.lock)
newm(nil, nil, id)
// Ownership transfer of _p_ committed by start in newm.
// Preemption is now safe.
releasem(mp)
return
}
unlock(&sched.lock)
notewakeup(&nmp.park)
// Ownership transfer of _p_ committed by wakeup. Preemption is now
// safe.
releasem(mp)
}
newm会进一步调用newm1、newosproc
func newosproc(mp *m) {
stk := unsafe.Pointer(mp.g0.stack.hi)
// Disable signals during clone, so that the new thread starts
// with signals disabled. It will enable them in minit.
var oset sigset
sigprocmask(_SIG_SETMASK, &sigset_all, &oset)
// 调用clone系统调用创建线程,并指定线程入口函数为mstart
ret := clone(cloneFlags, stk, unsafe.Pointer(mp), unsafe.Pointer(mp.g0), unsafe.Pointer(funcPC(mstart)))
sigprocmask(_SIG_SETMASK, &oset, nil)
if ret < 0 {
print("runtime: failed to create new OS thread (have ", mcount(), " already; errno=", -ret, ")\n")
if ret == -_EAGAIN {
println("runtime: may need to increase max user processes (ulimit -u)")
}
throw("newosproc")
}
}
进入调度逻辑
上方已指定线程入口函数为mstart,所以在新线程启动时,会执行mstart
该函数使用汇编实现,直接调用到mstart0,进一步调用到mstart1
TEXT runtime·mstart(SB),NOSPLIT|TOPFRAME,$0
CALL runtime·mstart0(SB)
RET // not reached
func mstart1() {
_g_ := getg()
if _g_ != _g_.m.g0 {
throw("bad runtime·mstart")
}
// Set up m.g0.sched as a label returning to just
// after the mstart1 call in mstart0 above, for use by goexit0 and mcall.
// We're never coming back to mstart1 after we call schedule,
// so other calls can reuse the current frame.
// And goexit0 does a gogo that needs to return from mstart1
// and let mstart0 exit the thread.
_g_.sched.g = guintptr(unsafe.Pointer(_g_))
// 初始化g0的原始栈信息,g->g0时切换到这里保存的PC和SP
_g_.sched.pc = getcallerpc()
_g_.sched.sp = getcallersp()
asminit()
minit()
// 如果调用newm时的第一个入参不为nil,在这里会执行这个入参所指定的函数
// Tips: sysmon的实现即使在newm时传入了一个永远不会退出的函数,会一直在这个位置运行,而不会进入到下方的schedule,进而陷入调度循环。
if fn := _g_.m.mstartfn; fn != nil {
fn()
}
// 进入调度循环
schedule()
}
寻找任务执行
func schedule() {
_g_ := getg()
println("enter newschedule,m id:", _g_.m.id)
if _g_.m.p != 0 {
println("m have p")
}
var gp *g
for {
// 加锁从全局队列寻找Goroutine
lock(&sched.lock)
gp = globrunqget(_g_.m.p.ptr(), 1)
unlock(&sched.lock)
if gp == nil {
// 没有可运行Goroutine时,挂起
newStopm()
} else {
break
}
}
// 运行寻找到的Goroutine
println("go to execute goroutine", gp.goid)
newEexecute(gp)
}
//go:yeswritebarrierrec
func newEexecute(gp *g) {
_g_ := getg()
// Assign gp.m before entering _Grunning so running Gs have an
// M.
_g_.m.curg = gp
gp.m = _g_.m
// G的状态变化 _Grunnable -> _Grunning
casgstatus(gp, _Grunnable, _Grunning)
gp.stackguard0 = gp.stack.lo + _StackGuard
// 切栈g0->g
gogo(&gp.sched)
}
后续计划
GM -> GMP
控制程序并发度
减小锁冲突
LocalRunQueue
减小调度时延
任务窃取
抢占调度
协作式抢占 信号抢占
自旋
防饿死
栈溢出检查
优先级调度
支持GC
支持Cgo
支持LockOSThread
支持Timer
支持epoll
支持cpuprofile
支持trace
本文由 LeonardWang 创作,采用 知识共享署名4.0
国际许可协议进行许可
本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名
最后编辑时间为: Jan 12,2022